Predicting Risk of Loan Default
What is the added value of an intrinsically interpretable model over an explained black-box model?

Explainability vs. interpretability
In practice, such techniques can provide local explanations for point predictions, or a partial view of how the model handles input data to make its predictions.
However, while intrinsically interpretable models simply and transparently show the user how predictions are made, explainability frameworks fail at delivering a global view of the model holistically and accurately.

Credit allocation requires highly understandable models
The prediction is then used to decide whether the homeowner qualifies for a line of credit and how much credit they should get. As stated by FICO, "without explanations, [predictive] algorithms cannot meet regulatory requirements, and thus cannot be adopted by financial institutions and would likely not be accepted by consumers."
For this application, we thus need an interpretable model. Let us observe how explaining a black-box model using popular explainability frameworks compares to an interpretable model built with Optimal Trees.

Explaining a black-box model fails to deliver a global view
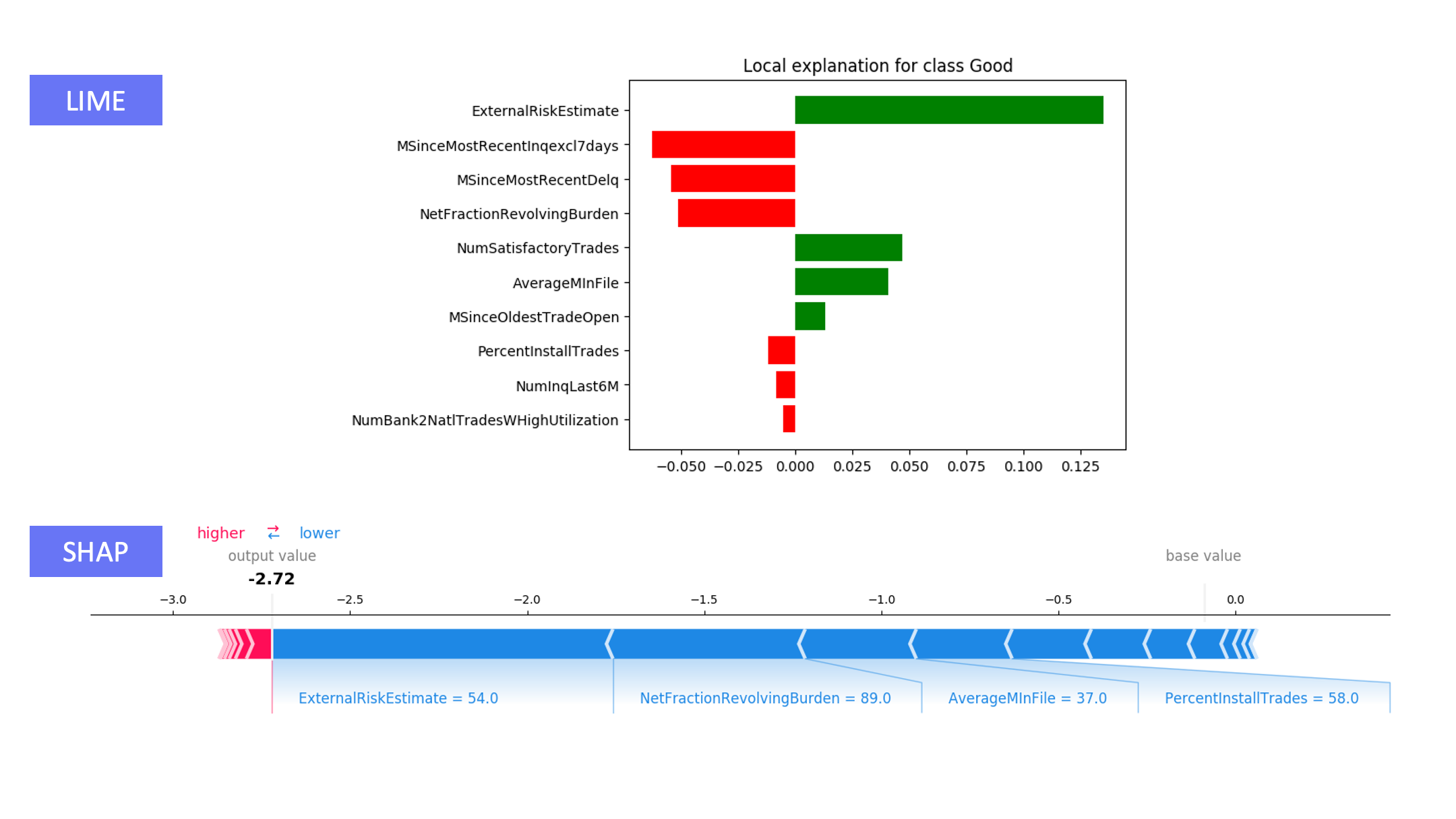
Certain frameworks, such as LIME, can generate an explanation for the prediction for a single point, but these local explanations are not necessarily globally consistent. LIME locally generates a linear approximation of the model, while real-world problems are often too complex to be modeled linearly.
SHAP generates a lot of diagnostic information about the model, both overall and for individual predictions, but it can be difficult to construct a succinct description of the prediction mechanism from this information. Moreover, the amount of output produced can often result in information overload and confusion.
Interpretable model displays flow of logic
With similar performance as a black-box model, Optimal Classification Trees yields a model which is both:
-
Globally interpretable
The tree visualization can easily be inspected to examine the transparent logic behind the predictions made by our model
-
Locally interpretable
For any applicant, we can derive from the tree a succinct, straightforward, and understandable justification for the prediction being made, using few features
The tree output where the user can zoom in on a particular path leading to specific predictions
Unique Advantage
Why is the Interpretable AI solution unique?
-
Concrete display of decision-making process
Financial institutions understand how the model classifies their customers
-
Simple to use
Optimal Trees can handle various data types (e.g. categoric or ordinal) without additional processing steps
-
Auditable and trusted
Interpretability enables compliance with regulations, facilitates auditing, and builds trust